Aplikacje SaaS i wykonywanie zadań w tle z AWS Batch i AWS Step Functions
Każda, nawet najprostsza aplikacja webowa wykonuje wiele zadań w tle, takich jak zmiana rozmiaru obrazów, importowanie informacji o produktach czy tworzenie sitemapy. Do tego, jeśli firma ma produkt objęty dystrybucją w modelu Saas, większość z tych zadań musi być wykonywana dla każdego klienta.
A to – zależnie od popularności produktu – może wymagać potężnej mocy obliczeniowej. Poza tym trzeba znaleźć sposób na szybkie dodawanie i aktualizowanie zadań bez popadania w technologiczny dług.
I przydałoby się nie wysadzić przy tym aplikacji, gdy każemy jej wykonać jakieś bardziej wymagające zadanie.
Na początku jest pokusa, by pozwolić aplikacji webowej, żeby sama sobie planowała i wykonywała zadania. W środowisku Java można dodać adnotację @Scheduled, a gdzie indziej wykorzystać node-cron i po sprawie – mamy mechanizm do obsługi zadań.
Wszystko pięknie… ale pojawia się parę fundamentalnych problemów. Zaraz po uruchomieniu drugiej instancji aplikacji trzeba zsynchronizować stan między aplikacjami, żeby to samo zadanie nie zostało zaplanowane dwukrotnie. Co gorsza, wszelkie zmiany w wykorzystaniu zasobów np. z powodu bardziej intensywnego zadania czy nagłego wzrostu liczby żądań mogą istotnie spowolnić działanie aplikacji. Nietrudno przewidzieć, że gdy jedno zadanie znacznie obciążające CPU zużyje wszystkie dostępne zasoby, nasza usługa może stać się niedostępna dla użytkowników. Jest to sytuacja jak z koszmaru, szczególnie w świecie SaaS, gdzie trzeba liczyć się z „problemem hałaśliwego sąsiada”.
Oczywiście można zastosować odpowiedni mechanizm synchronizacji zadań (zakodować procedury obsługi awarii, liczbę powtórzeń czy kolejkowanie) i np. zaplanować tylko przetwarzanie nocne. To często najszybsza metoda, ale jest mało skalowalna i zostawia nas z ogromnym długiem technologicznym.
Czy da się lepiej? Może jeszcze podzielić aplikację na część app-web i app-worker, wyłączając tę drugą z obsługi żądań sieciowych. Są różne frameworki, w tym Django, które sobie z tym poradzą, chociaż wymaga to zastosowania kolejek takich jak Celery czy RabbitMQ. W ten sposób awarie i błędy pamięci przestaną już zagrażać użytkownikom, a nagłe skoki w ruchu sieciowym nie wykoleją zadania w tle. Takie rozwiązanie jest dużo lepsze, ale wymaga odpowiedniego zarządzania i skalowania klastra roboczego w zależności od zapotrzebowania. Trzeba też pamiętać, że app-web i app-worker współdzielą sporą ilości kodu, co może dezorientować developerów i jeszcze bardziej zwiększać dług technologiczny.
Czy da się (jeszcze) lepiej? A gdyby tak aplikacja webowa zajmowała się tylko częścią webową? A aplikacje worker zajmowały się jedynie tym, do czego służą? Wrzućmy więc wszystkie zadania do lekkich, osobnych i uruchamianych na żądanie kontenerów, a metadane bierzmy z zewnątrz. To powszechna praktyka w świecie data engineering/science, w którym codziennie planowany i wykonywany jest olbrzymi graf DAG (Directed Acyclic Graph) z różnymi powiązanymi zadaniami. Gdy ma się odpowiednie narzędzia, takie usprawnienie działania aplikacji webowych nie wymaga umiejętności na poziomie data engineer – wystarczy tylko w pełni wykorzystać potencjał chmury.
Do tego potrzebne są dwie rzeczy:
- Po pierwsze, łatwe w obsłudze środowisko do zarządzania klastrami kontenerowymi, które automatycznie zapewni odpowiednie zasoby i uruchomi zadania z kontenera.
- Po drugie, coś do synchronizacji całego procesu. Tutaj z pomocą przychodzi AWS wraz z dwiema technologiami wspomnianym w tytule artykułu (kto by się spodziewał?).
AWS Batch, jak nazwa wskazuje, służy do przetwarzania wsadowego. Usługa ta pozwala na uruchomienie setek kontenerów, dostarczając tyle zasobów, ile tylko potrzeba. Dzięki wbudowanej kolejce wystarczy określić zadanie i moment jego uruchomienia, a AWS Batch zajmie się resztą.
Z kolei AWS Step Functions to usługa do synchronizacji bazująca na maszynie stanowej. W tym przypadku mamy tylko określić elementy do wykonania i ich kolejność. Tymi elementami mogą być funkcja Lambda, kontener Fargate, AWS Glue job czy AWS Batch. Usługa uruchamia te elementy, które są konieczne, przekazuje dane między nimi, wykonuje zadania równoległe i wykorzystuje zależności logiczne if/else. Cały proces można zaplanować według potrzeb.
Nasze know-how
Komponenty
Przedstawiona poniżej architektura ma charakter ogólny i radzi sobie z większością naszych zadań. Z jej pomocą można bez problemu wydobyć logikę potrzebną dla danego zadania i wykorzystać nawet 90% Infrastructure as Code (IaC) przy napotkaniu podobnego problemu. Nie można też zapominać o CDK czy Terraform – to świetne rozwiązania i warto z nich skorzystać.
Ogólnie cały proces wygląda następująco:
- Zadanie dzieli się na mniejsze części, które można poukładać równolegle (w aplikacjach SaaS to nic trudnego – wystarczy uruchomić to samo zadanie dla każdego tenanta).
- Następnie każdą z tych części uruchamia się w osobnym kontenerze.
- W razie konieczności proces można odpowiednio zaplanować.
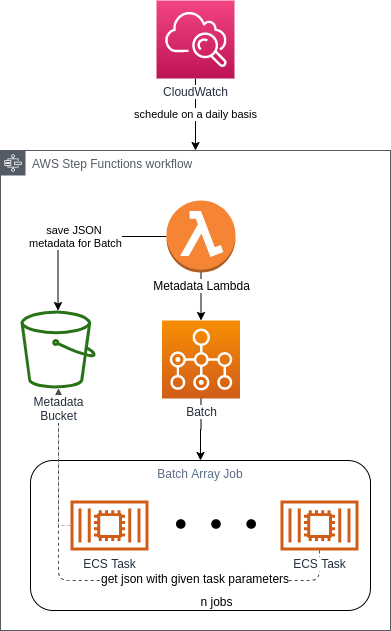
Metadata Lambda
Na początku procesu za pomocą funkcji Lambda określa się liczbę zadań do wykonania w AWS Batch. Wszystko zależy od tego, z jaką sytuacją mamy do czynienia – jeśli zadanie polega na zmianie rozmiaru obrazów, to „częścią zadania” może być tablica z 1000 ID. Wtedy każdy kontener miałby do przeprocesowania 1000 zdjęć. Jeśli celem zadania jest wygenerowanie sitemapy lub listy produktów do zaimportowania, to jedno zadanie przypadłoby dokładnie na jednego tenanta.
W tym miejscu warto też zająć się specjalną logiką: może akurat dany tenant potrzebuje dodatkowych parametrów? Albo niektóre parametry są niepotrzebne? Czy ostatnie zadanie dla tenanta zakończyło się pomyślnie i na razie można sobie darować dodatkowe obliczenia? Trzeba sobie odpowiedzieć na te wszystkie pytania i odpowiednio zakodować logikę. Warto też pamiętać, że kontener dobrze zastosować zamiast Lambdy, kiedy 15 minut to za mało na realizację zadania.
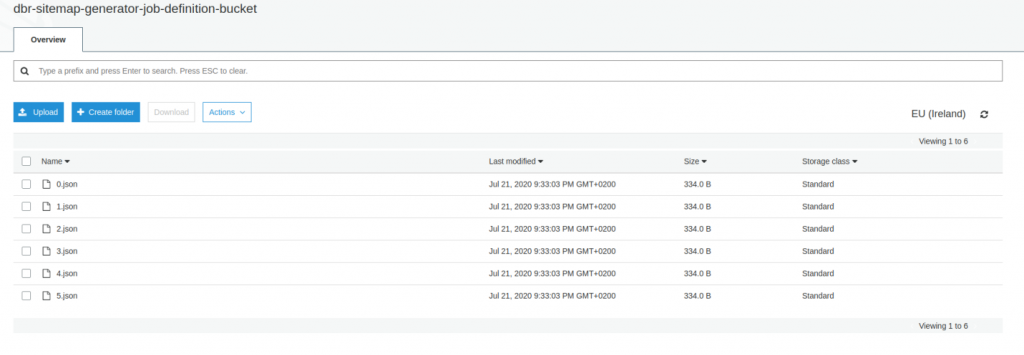
Metadata Lambda generuje n zestawów parametrów (każdy z nich odpowiada „części zadania”) i zapisuje je w buckecie S3. Moglibyśmy również pozwolić, by usługa Step Functions przekazywała wyniki z Lambda bezpośrednio do AWS Batch (bez użycia S3), ale stan Step Functions może podlegać różnym limitom (w kilobajtach). To pokazuje, że nasze rozwiązanie jest bardziej przyszłościowe.
Batch Job i kontener
Tworzenie Batch Job jest dość proste – wystarczy określić, ile vCPU czy pamięci powinno przypadać na jedno ECS Task i oraz przypisać mu konkretny obraz Docker. W tym przypadku używamy zadania o nazwie Array Job i ustalamy, że w Compute Environment ma być uruchomionych n równoległych, niezależnych kontenerów.
Kontener to niewielka aplikacja, która ma uruchomić zadanie o odpowiednich parametrach. I na tym jej rola się kończy. Tym samym bardziej przypomina ona plik skryptowy niż pełnoprawną aplikację.
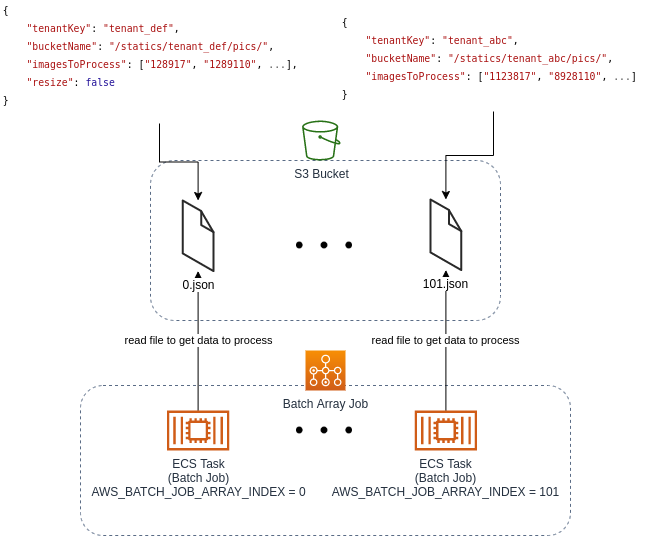
Jeszcze jedno – zastosowany kod musi być w maksymalnym stopniu ogólny i możliwy do ponownego wykorzystania – żadnego hardkodowania! Pierwszym krokiem jest odczytanie pliku S3 Bucket przy użyciu zmiennej środowiskowej AWS_BATCH_JOB_ARRAY_INDEX, by uzyskać dokładne parametry – każda instancja kontenera ma swój unikalny numer. Ten utworzony przez funkcję Lambda plik powinien zawierać wszystkie informacje potrzebne do wykonania zadania: nazwę tenanta, nazwę bucketu i tysiąc ID obrazów do przetworzenia.
Batch Compute Environment i Job Queue
Po zaplanowaniu Batch Job zadania przechodzą do Job Queue, gdzie czekają na wykonanie w Compute Environment. Są to de facto różnego typu ECS Clusters połączone z ASG/Spot Fleet. Można użyć swojego ECS Cluster albo pozwolić, by Batch zarządzał nim samodzielnie. Sami używamy klastrów zarządzanych przez Batch z instancjami Spot, co jest całkiem ekonomicznym rozwiązaniem. Wystarczy tylko określić minimalną i maksymalną liczbę vCPU. Przy minimum ustawionym na 0 klaster automatycznie wyzeruje swoje zapotrzebowanie na zasoby, jeśli w tle nie będą wykonywane żadne zadania. Nie korzystamy, nie płacimy!
Na tym etapie można także pośrednio ustalić maksymalną liczbę równolegle wykonywanych zadań. Jeśli kontener wymaga czterech vCPU, a cały klaster używa maksymalnie dwóch instancji EC2 po cztery vCPU w każdej, to w danym momencie będą wykonywane maksymalnie dwa zadania. Cała reszta będzie sobie zakolejkowana w Job Queue czekając na przeprocesowanie we właściwym czasie. Podobną zasadę można zastosować do alokacji pamięci. To dobry sposób, by oszczędzić swoją bazę danych i nie nadwerężyć innych zasobów.
Przy okazji trzeba pamiętać, że Job Queue może mieć przypisanych wiele Compute Environments. Można spróbować uruchomić zadanie najpierw w ramach instancji spot (wykorzystując dowolne Compute Environment A), a w przypadku braku zasobów przejść na instancje on demand (wykorzystując Compute Environment B). Można też określić kilka typów instancji EC2, które mogą być uruchomiane w Compute Environment. Wtedy AWS Batch – zależnie od obciążenia – spróbuje znaleźć w Job Queue instancję odpowiednią do zapotrzebowania.
Przebieg Step Functions
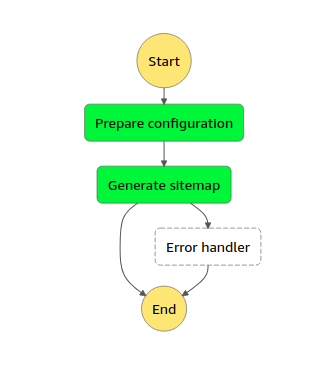
Usługa Step Functions zarządza całym procesem, spinając ze sobą wszystkie komponenty. Dzięki łatwości integracji z innymi usługami AWS można za jej pomocą uruchomić funkcję Lambda (lub kontener Fargate) i zaplanować Batch Job. W tym miejscu za pomocą maszyny stanowej definiuje się cały workflow i kolejność wykonywania zadań. Funkcja ta pozwala również określić procedurę obsługi błędów, na wypadek gdyby w workflow poszło coś nie tak. Podany przykład jest dość prosty, ale Step Functions ma nieograniczony potencjał: może służyć do zbierania danych historycznych o wszystkich udanych zadaniach i błędach, uruchamiania kolejnych zadań po zakończeniu Array Job, wysyłania e-maili do każdego tenanta czy uruchamiania zadań analitycznych w AWS Glue.
Pozostałe funkcjonalności AWS Batch
Przedstawiony wyżej workflow składa się z szeregu równoległych, niezależnych zadań, i jest dość prosty. Ale AWS Batch może dużo więcej. Zadania mogą być ze sobą powiązane i przekazywać sobie parametry w ramach samej funkcji AWS Batch.
Zadania N to N
Często się zdarza, że do każdego tenanta trzeba zaimportować wiele danych. W takim przypadku można pomyśleć o podzieleniu zadania na mniejsze części. Import to nie tylko pobieranie metadanych z zasobów zewnętrznych i zapisywanie ich w bazie danych. Proces ten często obejmuje wiele mniejszych kroków, takich jak weryfikacja danych, pobieranie dodatkowych załączników (dokumentów lub obrazów) czy przekształcanie danych do wymaganego modelu lub formatu i w ustalonej kolejności. Importując obrazy często je skalujemy, zmieniamy format i wykonujemy parę innych, z pozoru prostych operacji, które mogą zabierać sporo zasobów systemowych (a przy okazji przysporzyć pracy zespołowi Site Reliability Engineering (SRE), jeśli wszystko dzieje się w aplikacji webowej obsługującej żądania).
Na szczęście dzięki funkcji AWS Batch możemy podzielić ten długi proces na mniejsze części. Zamiast jednego kontenera do wykonywania wszystkich operacji możemy wykorzystać mniejsze kontenery z odpowiednio mniejszym zakresem zadań. Pierwszy kontener pobiera dane do systemu, drugi pobiera obrazy, a trzeci zmienia ich rozmiar. Jeśli ze skalowaniem pójdzie coś nie tak, obrazów nie trzeba ponownie importować – wystarczy powtórzyć tylko tę część, która odpowiada za skalowanie. To jednocześnie ułatwia rozwijanie i testowanie tych małych aplikacji.
Batch Array N to N Job pozwala na stworzenie listy zależności: najpierw wykonywane jest zadanie A, które po zakończeniu przekazuje dane do zadania B, a gdy ono się zakończy, rozpoczyna się zadanie C. Cały proces to zarazem Array Job, więc może być wykonany niezależnie dla każdego tenanta.
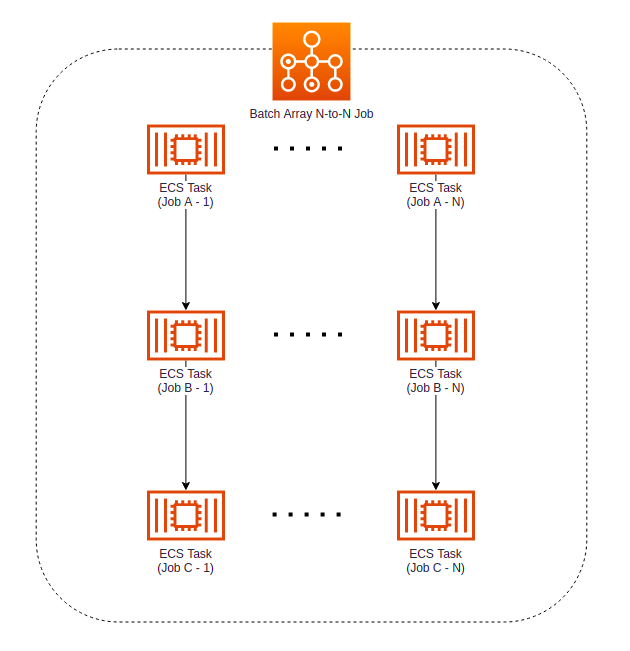
Można się zastanawiać, czy nie prościej byłoby użyć tutaj Step Functions i zaprojektować cały workflow w ten sposób:
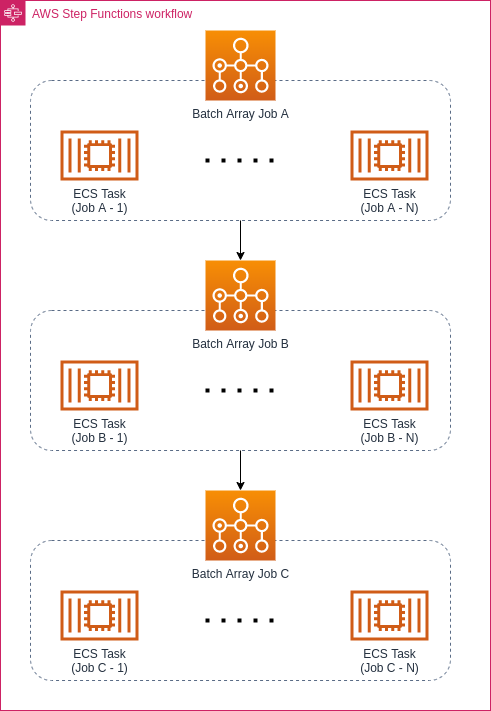
Widać tu jednak delikatną różnicę – jeśli workflow określi się jako N to N, każda sekwencja zadań będzie przebiegać osobno. Może być tak, że tenant z małą ilością danych szybko zakończy swoją sekwencję, a inne będą jeszcze na etapie zadania A. Natomiast przy użyciu Step Functions Job B może się zacząć dopiero po zakończeniu wszystkich zadań w ramach Job A. Jeśli nie chodzi nam akurat o taki workflow, lepiej zostać przy N to N, bo to pozwala na szybsze zakończenie całego procesu i gwarantuje lepszą paralelizację zadań.
Multi-Node Parallel Jobs
To kolejna ciekawa funkcjonalność AWS Batch, która pozwala uruchomić wybrane zadanie na wielu instancjach EC2, podczas gdy standardowo zadania zajmują tylko jedną instancję EC2. Multi-Node Jobs używa się w wysokowydajnych aplikacjach obliczeniowych oraz w modelach uczenia rozproszonego GPU. Funkcja ta jest kompatybilna z większością frameworków uczenia maszynowego wspierających rozwiązania oparte na komunikacji międzywęzłowej takie jak Apache MXNet, TensorFlow czy Caffe2.
Aby wykorzystać Multi-Node Parallel Jobs w AWS Batch, aplikacja musi być przystosowana do działania w systemach wielowęzłowych, więc kod musi wykorzystywać struktury odpowiednie do komunikacji rozproszonej.
Każde zadanie tego typu obejmuje uruchomienie głównego węzła, od którego zaczyna się cały proces, po którym uruchamiane są węzły potomne. Można sobie od razu darować środowiska wykorzystujące Spot Instances, gdyż funkcja Multi-Node Parallel Jobs ich nie wspiera. Mimo wszystko, gdy szukamy przystępnych środowisk obliczeniowych dla data science, AWS Batch wydaje się być najwłaściwszym rozwiązaniem.
Niespodzianki w pracy z AWS Batch
Mało użyteczny UI
Niestety interfejs użytkownika nie daje szansy na uzyskanie zbyt wielu informacji. Kiedy tylko coś pójdzie nie tak, znalezienie błędu i jego przyczyny wymaga przełączania się między Batch, ECS, CloudWatch i Step Functions. Społeczność podjęła tutaj inicjatywę i przygotowała kilka projektów, np. batchiepatchie, by wyeliminować tę niedogodność i stworzyć nowy interfejs użytkownika dla AWS Batch, ale po stronie AWS cicho w tej sprawie.
Szybkość reakcji Batcha to gwarancja szybkiej irytacji. Wszystko przebiega sobie jednym, niespiesznym tempem:
- Planujemy zadanie i czekamy aż trafi do Job Queue.
- Następnie czekamy, aż Compute Environment zauważy zadania w kolejce. Zauważył, ale brak vCPU, by je wykonać.
- Teraz czekamy aż system dostosuje się do zapotrzebowania.
- Tyn razem trzeba poczekać na sygnał do skalowania zasobów dla Spot Fleet/ASG.
- Potem czekamy, następnie jeszcze trochę czekamy – i zadanie uruchomione.
Nic tam nie sprawia wrażenia, jakby chciało zadziałać szybko. Nie jest to problem w przypadku żmudnych zadań w tle, ale gdy pracujemy nad rozwojem rozwiązania, może nieźle zirytować. Feedback loop można opisać jako niemrawy.
Debugowanie (i rozwój) Step Functions – łatwo nie jest
Definiowanie maszyny stanowej to nieuchronne spotkanie z plikiem JSON. Kiedy tam popełnimy błąd (a jeszcze do tego dodamy interpolację łańcuchów z Terraform), to ratunku nie znajdziemy w żadnym IDE. A komunikaty o błędach wysyłane przez edytor w AWS Console dużo nie pomagają. Testy? Darujmy sobie.
Po za tym IDE nie jest przydatne, jeśli chodzi o składnię przetwarzania input/output SFN. Do tych wszystkich $ i .$ też trzeba się chwilę przyzwyczajać.
Polecamy ciekawą dyskusję na temat Step Functions w serwisie Reddit. Dzięki niej można się dowiedzieć, że nic nie łączy developerów mocniej niż wspólne problemy.
Konfiguracja uruchamiania Managed Compute Environment za pomocą Spot Instances
Przy tworzeniu Managed Compute Environments z wykorzystaniem Spot Instances za kulisami jest bardzo ciekawie. W ramach tego procesu można określić szablon serwera wirtualnego (Launch Template) do wykorzystania przez EC2. Jeśli przy tym wybierze się jeszcze Spot Instances, to Batch wyśle w naszym imieniu Spot Fleet Request (oczywiście mamy AmazonEC2SpotFleetTaggingRole?).
Spot Fleet Request również wymaga Launch Templates, więc szablon z Compute Environment zostaje skopiowany. Niestety okazuje się, że jeśli zmienimy Launch Template w Compute Environment, zmiany te już nie pojawią się w Fleet Request’s Launch Template. Zastosowane przez nas narzędzie IaC (Terraform) na wiele się tutaj nie zdało. Musieliśmy zabrać się za debugowanie, zadając sobie pytanie: „skoro wprowadzamy zmiany do Launch Template to dlaczego nic nie zmienia się w skrypcie cloud-init?”.
Content-Type dla Launch Template
Jest to oczywiście opisane gdzieś w dokumentacji – warto upewnić się, że Launch Template ma postać MIME multi-part file (jak pokazano poniżej).
Uwierzytelnianie w prywatnym repozytorium
ECS umożliwia zaciąganie obrazów z niepublicznych rejestrów dzięki przydatnemu repositoryCrendentials w definicji zadania. Szkoda tylko, że Batch nie obsługuje tego parametru. Gdy chcemy skorzystać z zabezpieczonego, prywatnego repozytorium, trzeba skonfigurować ECS_ENGINE_AUTH_DATA dla EC2, na którym uruchamia się ECS agent. Można to zrobić w AMI albo dodać skrypt podobny to tego niżej w Launch Template dla Compute Environment. Ten kod pobiera dane uwierzytelniające z AWS Secrets Manager. Trzeba tylko sprawdzić, czy dana instancja ma wystarczające uprawnienia, aby wywołać API.
MIME-Version: 1.0
Content-Type: multipart/mixed; boundary="==MYBOUNDARY=="
--==MYBOUNDARY==
Content-Type: text/x-shellscript; charset="us-ascii"
#!/bin/bash
CREDENTIAL_ARN=<fill this>
REGISTRY_URL=<fill this>
CONFIG_FILE="/etc/ecs/ecs.config"
sudo yum install -y jq unzip
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/install
echo "Setting up ECS credentials!"
JSON=$(/usr/local/bin/aws secretsmanager get-secret-value --secret-id ${CREDENTIAL_ARN} | jq -r .'SecretString')
echo ECS_ENGINE_AUTH_TYPE=docker >> $CONFIG_FILE
echo "ECS_ENGINE_AUTH_DATA={\"${REGISTRY_URL}\": $JSON}" >> $CONFIG_FILE
sudo stop ecs && sudo start ecs
--==MYBOUNDARY==Rozterki data engineeringu
Przedstawiliśmy nasz szablon do przetwarzania wsadowego i zarządzania zadaniami w tle, który stanowi element jednego z rozwijanych przez nas projektów SaaS.
Czy da się (jeszcze) lepiej? W tym miejscu w zasadzie należałoby się zapytać: czy Step Functions ma być pełnoprawnym narzędziem do zarządzania workflowem z Batchem w roli silnika wykonawczego? Czy taki układ sprawdzi się w projektach z zakresu data engineering?
Na początku, na etapie MVP projektu czy produktu – na pewno tak. Usługę Step Functions można łatwo zaadoptować i zintegrować z innymi usługami AWS (takimi jak Glue czy Batch – bardzo przydatnymi w świecie danych) i naprawdę nieźle sobie ona radzi w nieskomplikowanych środowiskach. Jednak gdy powiązania i zależności między zadaniami stają się bardziej skomplikowane, zaczynają pojawiać się problemy.
Usługa Step Functions opiera się na modelu maszyny stanowej – analizujemy obecny stan procesu i na tej podstawie określamy kolejne zadania. Można uznać, że Step Functions to w zasadzie skomplikowana maszyna o logice if/else. W data engineering dużo wygodniej jest posługiwać się grafami DAG (Directed Acyclic Graphs), które działają według modelu: ukończ pierwsze zadanie, następnie zrób dwa równocześnie, a w kolejnym kroku połącz wyniki itd. Niestety ani Step Functions, ani żadna inna usługa AWS takich operacji nie obsługują.
W takim razie co z innymi rodzajami Batch Jobs, które wspomnieliśmy w artykule? Czy nie można dzięki nim stworzyć czegoś, co naśladowałoby DAG? Cóż, gdy się spełni określone wymagania, to przez chwilę wszystko będzie działać. Jednak wcześniej czy później poziom skomplikowania zależności logicznych wzrośnie i Batch dostanie zadyszki. A walka z frameworkiem, takim jak SFN czy Batch, nie będzie łatwa.
Dodatkowo parę rzeczy powinno nam dać do myślenia – kiedy jedno z zadań SFN się wysypie, nie można tak po prostu zastosować poprawki i działać dalej od tego samego miejsca, gdyż całe zadanie oznaczane jest jako błędne i graf trzeba zacząć od nowa. Samo to już sprawia, że SFN nie nadaje się do projektów z zakresu data engineering, gdzie obliczenia często ciągną się godzinami (do tego jeszcze trzeba pamiętać o niedogodnościach związanych z debugowaniem/ testowaniem, obliczeniami równoległymi i zależnościami logicznymi). Co prawda możemy wykorzystać mechanizmy ponownych prób, ale to wiele nie zmienia. Jednak na potrzeby data engineering raczej polecamy Apache Airflow albo podobne narzędzie do obsługi planowania DAG, które można uruchomić w AWS EKS i w pełni zintegrować z resztą usług AWS.
Werdykt
Na szczęście w przypadku większości aplikacji webowych zadania w tle nie są aż tak skomplikowane i uzależnione od innych operacji. Nic nie stoi na przeszkodzie, by zadania takie jak zmiana wymiarów obrazów, generowanie sitemapy czy raportów odbywały się niezależnie. A w świecie SaaS mogą one być procesowane równolegle dla każdego tenanta. Jak już pokazywaliśmy, to doskonałe uzasadnienie dla sięgnięcia po SFN i Batcha.
Czy to najlepsze rozwiązanie na rynku? Jak to zwykle bywa w IT, odpowiedź zależy od skali i wymagań projektu. Pewnie sprawę załatwiłby periodic job na poziomie frameworka, z którego korzysta nasza aplikacja. Takie rozwiązanie można by wdrożyć szybko i bez ingerowania w infrastrukturę projektu.
Niemniej to jest niebezpieczny kompromis, którego efektem mogłoby być zbytnie obciążenie systemu, szczególnie jeśli działamy w modelu biznesowym SaaS. W takiej sytuacji nawet niewielki wzrost liczby tenantów wprost przełożyłby się na gorszą wydajność aplikacji i zwiększyłby dług technologiczny. Wyobraźmy sobie, że aplikacja pada, bo jeden z klientów miał trochę więcej obrazków do przetworzenia. Takie coś na pewno nie wyjdzie na zdrowie naszemu biznesowi.
Uwzględniając fakt, że w kodzie produktu głęboko osadzone są różne technologie AWS, a sam produkt zyskuje na popularności, długo nie musieliśmy się zastanawiać. Dzięki połączeniu CloudWatch, Step Functions, Batch, Lambda i S3 możemy przetwarzać duże ilości danych bez szkody dla systemu. I to rozwiązanie zdecydowanie polecamy każdemu, kto jest na podobnym etapie, co my.